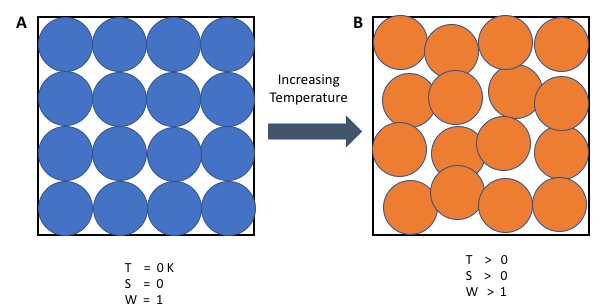
I’ve long struggled with the concept of entropy. Part of the reason is the way it’s often described in popular science accounts, which typically seem subjective and value laden. The most common way of describing it is the amount of disorder in a system.
But disorder according to who? A room that appears messy and disordered to an outsider, like my office, might be the owner’s idea of pragmatic organization. Of course, the owner typically knows the causal history of the items in the room, and so might know where everything is, but to an outsider, it’s a mess with lots of uncertainty within it. (Yeah, I know I’m full of baloney on knowing where everything is. But it’s not like knowledge of where things are is any better after someone comes in and straightens everything into nice neat stacks.)
That relates to another typical description of entropy, the amount of uncertainty in a system, or perhaps the amount of hidden information. But again, that seems subjective. If you know more about the configuration of a system than I do, does that mean it has a lower entropy for you than for me? This seems wrong for what’s supposed to be an objective property of a physical system.
In my own mind, I typically think of entropy as the extent to which a system has approached its final causal state, its resting ground state, which fits with Rudolf Clausius’ decision to use the Greek word for transformation to describe it. But that’s admittedly somewhat tautological, describing entropy in terms of its effects rather than what it is. And it doesn’t provide any insight on how to quantify it.
Of course, scientists like Clausius, Ludwig Boltzmann, Josiah Gibbs, John von Neumann, and Claude Shannon have already done the heavy lifting here. The equations that have been hammered out describe entropy as the number of states that a system can be in.
Shannon’s inclusion here is interesting, because his contribution comes from the direction of information theory. It turns out that the measure of a system’s entropy is the same as the measure of how much uncertainty can exist in it, in other words, of how much information it would take to describe it. So a possible way to describe entropy is the quantity of a system’s information.
Of course, this is in terms of Shannon information. Many object to the word “information” here, because they don’t perceive it as necessarily semantic information, that is, meaningful information. A common view is that information is data plus meaning, and Shannon information seems like just raw data, physical patterns, at best.
But this raises the question of what we mean by “meaning”. (Yes, I’m pondering the meaning of meaning. Sorry.) What gives data meaning? A lot has been written about this. My own take is that meaning comes from the causal history that resulted in the physical patterns we call data, and the causal effects those patterns might have in the future. It’s the relationship between the data’s past and future light cones. Put another way, meaning comes from the data’s relationships with its environment.
In this view, data always has meaning. We often just don’t know what it is. For example, tree rings have semantic meaning for anyone who understand their causal history, in how they are produced in the tree’s development and growth. But without that knowledge, tree rings are just a peculiar pattern.
That means data is always information, although it may not be semantic or useful information for me or you. Put another way, semantic information is a subset or a type of physical information, and whether or not a piece of information is semantic depends on our knowledge of its causal history and potentialities. In other words, the distinction is relative to the infomee.
Last year I tentatively defined “information” as causation and asked if anyone could find distinctions between these concepts. I think I might have just found one, because a high entropy system has a lot of physical information, but little causality left in it, at least without outside energy. That seems to imply that information is a result of causation rather than causation itself. But in a relatively low entropy system, information can still have causal efficacy. So maybe a better way to describe it is as a snapshot of causal processing. That also has the nice benefit of keeping a meaningful distinction between information and information processing.
Since the universe is always producing entropy, this has the interesting implication that the universe is always producing information. The universe is an information producing system. That probably sounds more profound than it is, since all we’re really saying here is the universe is always increasing in complexity. (I do wonder what this means for the state of the universe after heat death, which doesn’t seem particularly complex to me, but is usually considered a high entropy state.)
This relation is also making me take another look at brain entropy theories. The idea that a brain is a high entropy system seems very counter-intuitive. But I suspect it seems that way because of the value-laden way we think about entropy. It’s similar to the fact that when someone starts learning accounting, they often have to unlearn the idea that credits are always good and debits bad. Or the idea that bacteria in our body is always bad, when it turns out they play an integral role in digestion and other processes. In that sense, the idea that the brain uses entropy might fit right in.
Anil Seth, in a recent interview with Sean Carroll, talked about transfer entropy, and how it’s been shown to be the same as Granger causality. It reminded me of the study that found information hubs in the brain (with the idea that they’re the hubs of the global workspace) by using a technique called NDTE (normalized directed transfer entropy). Talking in terms of entropy rather than information seems like a more cautious way to discuss it, avoiding the definitional morass between physical and semantic information.
All of which is to say, entropy, information, and causality are distinct concepts, but they seem intimately tangled together into a tight conceptual hairball. At least, that’s the way it seems to me today.
What do you think? Do the relations I’m describing here make sense? If not, where is the logic going wrong, or what am I missing?

Heat death occurs when the universe reaches its maximum state of entropy. Information, in the sense you defined it, will then no longer increase. Strictly speaking, this is a limit that can be approached but never reached. Does that make sense?
Footnote: In this discussion of entropy, information, and causality, you omitted the concept of “work” .No worries, we all like to avoid work where possible 🙂 But work in the thermodynamic sense is a useful concept for tying the discussion together. A low entropy system has the capacity to do work. As work is done, entropy increases until no further work can be done and entropy has reached a maximum. Work is usually discussed in terms of heat engines, but I don’t see why you can’t apply it to brains. Brains must do work in order to acquire information. In so doing, their entropy increases. And causality makes work happen, so it all ties in. The advantage of thinking about work is that it’s a well-defined physical concept that is objective and can be measured.
LikeLiked by 4 people
On heat death, thanks Steve. That does make sense. It also occurred to me that, while the current differentiations (information) will become progressively less pronounced, they may also never reach complete zero, just continuously approach it. That, and due to the ongoing expansion of the universe, those differentiations would be stretched beyond any one observer’s Hubble volume, and therefore no longer observable, but that doesn’t mean they wouldn’t exist.
“Work” would have been a good word to use when I was talking about causal efficacy. I do think I would have had to make clear it was work in the physics sense of force and displacement. Oh well. I always know what I should have said after the discussion. 😉
Definitely brains do work. They’re also the most energy hungry organ in the body. All that energy is likely needed for a system that operates at and utilizes high levels of entropy.
LikeLiked by 1 person
Hi Steve,
I’ve always had trouble with the concept of entropy, and largely on the lines that Mike expressed. In physics class they’d talk of order and disorder, but never seemed to define these terms. You may have clued me in on this however if I’ve interpreted you right. Check me here if you don’t mind.
If an ultimate definition for entropy is a system that can do no work (measured in joules, so in terms of force times distance this would be in Newton meters), then an ultimate universe heat death would be where the movement of matter in general peters itself out to a temperature of absolute zero. To approach such a state apparently matter would need to be spread out enough so that gravity doesn’t packed it tightly enough together for there to be any nuclear reactions or anything else. But you also said that it’s thought that this can never be reached completely, so I guess even with extreme entropy, gravity and time should bring matter back together again and so possibly even create the extremely low entropy of a Big Bang?
LikeLiked by 2 people
Eric, I don’t think the Big Bang is ever coming back. In the far future, matter will be so dispersed that there will be no interactions between particles. The observable universe will be empty, dark and cold. Gravity will have been defeated by the expansion of the universe.
LikeLiked by 4 people
Sometimes it seems like the life cycle of universe from the inside might be like the life cycle of a black hole from the outside with the Big Bang corresponding to the collapse of the black hole and heat death corresponding to evaporation of it.
LikeLiked by 1 person
Sounds good Steve. And that account does conform with the second law of thermodynamics (which the video that Mike just posted below for James reminded me of). If gravity ultimately brought everything together again after a heat death, then it would seem that a high entropy state could lead to a low entropy state and so conflict with that supposedly supreme law. But then from where we sit, isn’t such a retraction possible? I suppose in that case the second law of thermodynamics would be saved by saying that entropy would continue to increase because even in apparent heat death, the system would still have the potential to do the work of recombining and exploding again. Or couldn’t we say that entropy always increases when the universe is expanding, and it always decreases if/when it’s retracting? I suppose it’s all human convention, though to me that seems like it may describe things a bit more effectively, that is if matter doesn’t ultimately retract again.
LikeLiked by 1 person
Eric, it is theoretically possible for gravity to bring the universe back together again, although the discovery that the universe is actually accelerating in its expansion seems to remove that option. I have heard people argue that if the universe contracted again that the second law of thermodynamics and even time itself would be reversed, but I don’t understand the logic of that. In my view, the direction of time would continue, and entropy would continue to increase. We would not simply rewind back to the big bang.
LikeLiked by 2 people
Yeah that sounds right to me Steve. So let’s say that stars and black holes in general “burn themselves out”. Then with enough time even if gravity were to bring some of the resulting low mass structures together again, they’d either remain inert or become massive enough for nuclear reactions and lose their masses just like stars do today. So I suppose even given dark matter, things should never all come together again. Entropy should continue to increase and I guess time should continue on, not that I understand the mechanics of time.
LikeLiked by 1 person
Roger Penrose has pointed out how different a Big Crunch would be from a Big Bang. As the Crunch occurs, matter unavoidably falls into black holes, and black holes merge. The collapse is therefore “ragged” and “lumpy” — in utter contrast to the Big Bang, which we believe started in a very, very low entropy “smooth” and “even” state that coalesced into structure due to gravity.
The notion that time or entropy would run backwards during such a Crunch is just a false one. All those final black holes would contain enormous amounts of entropy. Definitely not a rewinding!
LikeLiked by 1 person
From the peanut gallery…
If dark energy is real (which few doubt), it’ll insure the universe never collapses. If the Big Rip scenario is true (which some doubt), that expansion eventually rips apart atoms. According to some scenarios, given enough time, and assuming anything with mass eventually decays, all that remains are massless photons and gravitons. (In Roger Penrose’s Conformal Cyclic Cosmology model, this is somehow the same as the Big Bang of the next version of the universe.)
FWIW, I suppose it’s just wording that means the same thing, but I’ve never loved the phrasing that life uses entropy. To me, life (and anything that does work) creates entropy. As Mike pointed out, brains are fuel burners, and an important part of their support structure is cooling away that entropic waste heat. If anything, I’d say that life is a battle against entropy.
LikeLiked by 1 person
I think Shannon was talking about the potential or the capacity of a system to contain or carry information in the abstract. He could have just as well assigned variables and entered them as such into an equation for determining storage capacity or bandwidth. I think most of us use the term information as something that was or is or could be useful for some purpose; that is, it has a utility value to someone or something. Somehow, I don’t think it would likely be appropriate to equate information in its common usage with entropy. I saw an interesting youtube lecture several days ago in which the consistent ineluctability of entropy was questioned, not in the ultimate sense but at every step along the way. Life resists entropy by self-organizing non-living and living particles into increasingly complex systems. Of course, eventually, every living thing dies, but later it may or may not recombine into other living systems. Bottom line: the universe does not consistently disperse toward equilibrium at every Planck moment but does a sort of cha-cha, two steps forward, three steps back (or vice-versa).
LikeLiked by 3 people
On the term “information”, that gets to the distinction I made in the post between physical and semantic information. The reason I’m okay with using “information” to refer to the physical variety is it is always possible for it to become semantic. I used tree rings as an example in the post, but another would be spectral absorption lines; taken by themselves, they mean nothing, but once we are aware that they change depending on what element the light passed through, they become semantic information, information that allows us to deduce what the stars are made of.
Life does resist entropy, for itself. But the thing to remember is that for any system to lower entropy (or keep it the same while still doing stuff), it must increase entropy somewhere, even if outside of itself. So overall, life isn’t the universe resisting entropy, but actually a mechanism to speed it up. I keep meaning to look up Eric Smith’s work, which reportedly posits that life may be an inevitable mechanism for releasing pent-up potential. So in the universe, if stuff is happening, entropy is increasing, somewhere.
LikeLiked by 2 people
Somebody, I think. wrote that life doesn’t violate the Second Law of Thermodynamics but it violates the spirit of it.
LikeLiked by 1 person
I’ve thought of it as climbing a sand dune: two steps up, slide one back. Takes so much energy! (I quite agree that Shannon entropy is a different topic.)
I think it’s an amazing property of the universe that energy+time, contrary to thermodynamics, can result in increasing complexity. Even the fusion of hydrogen into helium in the Sun is a manifestation of that. Life uses that property to very temporarily and locally decrease entropy (although, as Mike says, it’s always paid for).
LikeLiked by 1 person
As you may know, this topic is the basis of my current intellectual project (consciousness), so I’m just going to sketch where I am and nail down the definitions I’m using, and then you can decide if these are useful for you.
Causation
I use a Constructor Theory-esque framework: every physical process looks like:
Input (x1, x2, …xn) —> [mechanism] —> Output (y1, y2, …ym)
We describe this by saying the mechanism *causes* the Output when presented with the Input. So any reference to “causation” refers to a such a physical process. This definition of causation will be related to information (see below), but it renders statements like “a high entropy system has little causality left” and “information can have causal efficacy” as problematic (and to be avoided 🙂 ).
Information
The term “information” is used in so many ways that it’s best to avoid the term as much as possible if we want to explain what goes into all those uses. So here goes:
Causation creates correlation.
The output of a process is correlated with the Input and the Mechanism to some percentage. [I’m pretty sure I can say this, but I need to do some real digging in information theory to be more confident about exactly how to say it.] Basically, knowing the output tells you that there was an input and the mechanism. Pretty sure the information theory version would say that the output shares mutual information with the input/mech. An important result is that every physical system has a correlation with the systems that “caused” it.
Every physical process is an information process.
Information theory says every information process can be described as some combination of COPY, NOT, AND/OR. (AND/OR are interchangeable, in that any AND can be duplicated by a combination of OR’s and NOT’s, and vice versa.) So what does a COPY copy? The answer is the correlations. If we say that A is COPY’d to B, then B has the same correlation that A has(had). Thus, every physical process does a COPY. For a simple process, like A->[mech]->B, B is correlated with A. Now given B->[mech2]->C, C is correlated with B, which is correlated with A, so C is correlated with A. C is a COPY of A. Note: C is also a COPY of B, and a COPY of mech2, and a COPY of mech. The upshot is that C is correlated with LOTS of systems. But the degree (percentage) of correlation will be different between systems. (In fact, C will have some degree of correlation with *every* system, past and future, where it is part of the chain of interactions.)
*
[gonna end this reply here, but the following are the next major statements in this thread:
Semantic information refers to a specific correlation (out of all the possible correlations).
Semantic info. is determined by the interpreting process.
Representation requires 2 processes: 1 create system with semantic information, 2. interpret. Okay
Unitrackers are systems that perform process 1 of representation.
Okay, chew on that]
LikeLiked by 2 people
Usually when a term has a lot of uses, my strategy is to prefix or qualify it, which is why I used “physical information” or “semantic information”. Unfortunately the information field, like so many others, isn’t consistent with its terminology. I got the “semantic” prefix from Luciano Floridi in his book: Information: A Very Short Introduction. However, the word “semantic” doesn’t occur in Caleb Scharf’s book on information. Scharf is an astrophysicist, so he tends to use “information” in the manner that physicists do, as physical information. For his part, Floridi resists that usage, preferring not to call Shannon information, “information”.
I’m on board with causation creating correlation. In fact, it’s worth noting that we never observe causation. Ever. David Hume pointed out that we only observe correlations. It’s the relationships between correlated variables that allow us to form a causal theory. (Usually at this point, someone jumps in to say that correlation doesn’t imply causation. But that’s wrong. It doesn’t establish causation, at least between the correlated variables, but it does imply some common causation in their history.)
Another thing worth noting is that an AND/OR process can result in correlation between large numbers of variables.
A final note about correlation (for this comment). At the quantum level, we refer to it as entanglement. (Although a lot of physics papers stick with “correlation”.) Which means that correlation and entanglement are part of that tight conceptual hairball.
[I think I’m onboard with everything you said at the bottom. I’ll just note that it implies that a particular pattern can have multiple semantic interpretations.]
LikeLiked by 1 person
Heat death of the Universe does seem like an anti-pattern to maximum entropy / maximum information. Perhaps it’s not just the distribution of matter but the energy potential in combination with the distribution — which would promise additional chaos — which would maximize to a tipping point… And then contract down to where/when all potential energy was spent. In the end, leaving a perfect distribution of matter and reduced but stable information.
This post hurt my brain. Can we get back to anime?
LikeLiked by 2 people
Steve and I above might have worked out how heat death can avoid being an anti-pattern. But what you say here about energy potential might be part of it too.
Haha. I got the impression you were seeing too much anime. Don’t worry, there will probably be more anime (or other entertainment) posts before we get back to another one like this. 🙂
LikeLike
(I have not read any of the other comments, yet.)
This is a deep weedy topic. I quite agree entropy and information are general topics with wide application that need specific definition to discuss seriously. The casual definition equating entropy with disorder is handy but kinda vague (although I’ve used a version of it). I like the definition involving microstates and macrostates, but it still requires defining the macrostates.
FWIW, I think the uncertainty view works out to the same thing, but I think it’s something of a ‘this is what entropy implies’ abstraction. As you kind of point out, linking entropy with knowledge seems to make it relative. (FWIW², one way to disambiguate ‘messy-but-I-know-where-everything-is’ from ‘everything-in-its-place’ is to point out the implicit map that indexes the heap of ‘everything’. A formal ordering, or personal knowledge of location, both have low entropy. However true disorder — randomness — has no map and is therefore high entropy.)
I see Shannon entropy as in a different class that concerns data transmission and storage. It’s important there because it’s about the limits of what we can expect from those systems. Boltzmann entropy is an important understanding of thermodynamics, but I see it as consequential — as an emergent property of physical systems. It’s a statistical behavior, not a fundamental one. (Nothing other than odds prevents entropy from decreasing. It’s just that those odds are really huge.)
Information is even trickier. As you say, on one view, what isn’t information? Probably what’s needed is a notion of useful information. The high-entropy heat death may contain a lot of information about the low-energy photons flying around (and gravity waves), but none of it can be used for anything. And there isn’t enough energy to extract that information. There is, I think, a relationship between information and work similar to the thermodynamic one of energy and work.
(As an aside, I would have thought the brain itself had very low entropy given its complex structure and function? Is it the function that deemed high-entropy? That still seems weird to me. Functioning consciously seems an apex state — a kind of performance peak — requiring low-entropy. What makes it high-entropy?)
LikeLiked by 2 people
Good point that uncertainty is basically the same as the microstate / macrostate thing. It seems like a logical step toward the more general answer, which is the measure of the overall number of microstates in the system. In a sufficiently complex system, our ability to know it’s full state seems problematic, requiring a lot of energy to do it (if it’s even possible). As you note, an index can be formed of the items in an office, but it requires energy to do it, and the entire office + index system still seems like it has a lot of entropy. It takes a lot more energy to do something with it than with a simple room with few items in it, although you can do more complex things with the high entropy version, provided you have enough energy.
Shannon entropy was definitely developed with an eye toward understanding transmission of information (or storage) while Boltzmann was focused reconciling particle dynamics with thermodynamics. The story was Shannon was wrestling with what to call his version. John von Neumann was the one who advised him to call it “entropy”, since mathematically it was the same, and since no one knew what entropy actually is, he’d “always win the debate.”
Entropy is definitely an emergent phenomenon, along with the second law of thermodynamics. Supposedly it’s the only irreversible law in physics (unless maybe there’s an ontic wavefunction collapse, but then one of those might be a special case of the other), and as you stated, it’s an irreversibility in practice rather than in principle, since there’s always an infinitesimal probability it doesn’t increase.
Useful information is what I was trying to get at with the semantic information concept. Of course, “useful”, like “semantic” depends on the informee, if there is one. Good point about all the information in the photons and gravitational waves. I’d forgotten about Penrose’s theory.
I had the same reaction when I first heard about entropic brain theories. It actually sounded a bit contrived and too low level, like maybe physicists overapplying physics, so I didn’t pay much attention. I haven’t really had a chance to dive into any of the papers again, but this snippet from the abstract of one of the papers gives an idea of how they’re approaching it.
https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0191582
Similar to the messy office scenario above, I think using this high entropy may be the reason brains require so much energy. Information processing has a thermodynamic cost, as any owner of a hot laptop knows all too well.
LikeLike
You’re right, there’s a Maxwell’s Demon aspect to the idea of actually measuring the entropy of a system. So yeah, our ability to quantify entropy in a real system usually is very limited and usually based on a simplified model of that system. What I like about the micro-state/macro-state view is that, even if we can’t precisely identify the macro-states, they do exist (identifiably in models), and entropy can be understood as the system migrating to more common (“larger”) ones.
An office with very little in it has a lower maximum entropy than an office with a lot of stuff. (Maximum entropy depends on the total number number of states a system allows.) Put in terms of uncertainty, with a sparse office, it’s easier to be certain a change has occurred, but in a busy office it’s much harder. (More specifically, it takes more memory and effort to remember the busy office.) FWIW, I see an office+index a low-entropy system in itself, but as you say, a large amount of entropy is generated creating it. That entropy has wandered off as unrecoverable waste heat.
I think there’s a difference between the reversibility of physics and the possibility that entropy decreases. Usually the former implies a negative time signature — time literally going backward. However, entropy can decrease while time goes forward. It’s just hugely overwhelmingly we’re-talking-giant-numbers unlikely. (In fact, it happens all the time, tiny “violations” in entropy, but there’s a ratchet effect. Given equal probability of moving to a smaller configuration versus a larger configuration, larger always ultimately wins. It’s like a rock on the slope of a hill in an earthquake. It might jiggle upwards briefly, even for a few steps, but downhill always wins.)
I don’t think we can get away from the bond between information and the implicit or explicit map the informee uses to makes sense of that information. I suppose we could call the raw statistics that describe reality as “data” and the things we actually choose (or are able) to measure as “information” but that’s just semantics.
“Entropy measures the variety of configurations possible within a system, and recently the concept of brain entropy has been defined as the number of neural states a given brain can access.”
I think they’ve confused entropy with complexity. There are indeed a huge number of possible states, but brains only occupy a single state at a time, and only a small subset of states in the right sequence creates consciousness. It’s because they maintain such a low-entropy state that they consume so much energy. As you mentioned about the messy office, it takes energy to either clean it or create a sorted index for it. (Refrigerators are another example of a system that burns a lot of energy maintaining a low-entropy state.)
We might say brains are systems with a very large maximum possible entropy, although they’re usually in low-entropy states functionally. In analogy to the canonical example of gas in a room, an even distribution is a max entropy state whereas all the gas in one corner is a low-entropy state because far fewer of the possible configurations of the room look like that. Functionally the brain seems like the gas in one corner — a state the brain works hard to maintain (as we would for gas in a corner).
As an aside, totally agree that information processing costs energy, but laptops are so hot because we want that processing done fast. The annoying heat comes from how CMOS transistors speed up switching by temporarily short-circuiting every time they switch states. Billions of short-circuits per second do create some heat! We waste a lot of electricity in the name of speed.
LikeLiked by 1 person
Interesting point about maximum entropy. That implies that a RAM chip with all the bytes zeroed out has less entropy than one filled with data. Which makes sense under both epistemic and objective notions of entropy.
I suspect what’s making you say the office plus index has less entropy than just the office itself it because our ignorance of the system is lower? But what happens if, after you painstakingly put the index together, I lose it. Does my losing it cause the office’s entropy to go up? Unless the configuration of the office has physically changed, that seems weird. How do we reconcile an epistemic idea of entropy with a more thermodynamic one? (I pasted a segment of some remarks Sean Carroll makes on this, but they’re in reference to a paper he did on it, which I might have to look up, although I suspect it will be too mathematical for me.)
I’ve never taken the idea of reversability to necessarily imply negative time (assuming I’m understanding what you mean by that phrase). To me, it’s always just meant that with most physical laws, in isolation, all the forces could have been reversed. It’s just that when we consider real systems in an overall environment, we get an ever increasing number of microstates, most of which are incompatible with simple reversability. (We might be saying the same thing.)
On brains, I’ve noted to a few other people in this thread, I might have been mistaken to use the adjective “high”. A brain’s entropy might not be that much higher than any other system, at least any other biological system. What might distinguish brains is their utilization of their entropy, although as also noted, this could be just a roundabout way of saying it processes a lot of information.
But I think that paper is indeed equating entropy with complexity, in the sense of the number of micro-states. Increasingly that’s what I’m seeing from both the physics and neuroscience side. And the straight micro-state quantity seems implied by what I understand of the math. So what would you say distinguishes entropy from complexity? Is it just the epistemic aspects?
LikeLike
Yes, exactly. In terms of stored data patterns, RAM comprised of all zero bits (or all one bits) has zero entropy because each is a singular state, and log(1)=0. In contrast, as physical objects that consume electricity, the chips themselves generate entropy (heat) regardless of data pattern stored.
Office entropy has poorly defined notions of “ordered” versus “disordered.” As you’ve pointed out, most popular accounts based on such notions leave one thirsty, and I think that might be due to the difficulty of defining “order” for something like an office. We need my grandma’s aphorism: “A place for everything, and everything in it’s place.” Such a definition made precise creates a singular state with zero entropy. But then we need a definition of disorder. Moving a chair to a new location seems to change the order, but what about moving it just one inch? Defining macro-states here is very hard.
Then what “indexes” an office? A set of photographs capturing the office in some “perfectly sorted” state would do. Or a detailed text description with measurements. Or good memory. They all define the singular zero-entropy state. So when I say the office+index has low entropy, I am really referring to the index.
If the index is lost, and no other means exists to define the singular “perfectly sorted” state, then the low-entropy part has been lost and the office state is indistinguishable from all others. (Of course there still exists human notions of disorder. Upside-down chairs, scattered papers, etc. These would still impose vague notions of entropy on the office.) The situation is similar to how data is stored on your hard drive. Programs and data are typically broken up into disk sectors which are distributed per some disk allocation algorithm. The disk index allows finding and re-creating them when needed. The sectors+index are low-entropy, but if the index is trashed, the disk’s data becomes little better than random.
For entropy I like the example of a CD collection that’s sorted by artist, date, title, and has rules for ordering multiple releases such as studio and live versions. In virtue of its sorting rules, the collection has a well-defined singular zero-entropy state. It also has well-defined macro-states. The first is the state one-CD-out-of-place, and the number of combinations is precisely quantified from the total number of CDs. The next state involves two CDs, then three, four, etc. The number of possible combinations grows with each additional CD. Maximum entropy is all CDs out of order and that state has the most combinations.
Right, the physical forces can be reversed. (Mathematically, it’s usually done by changing the sign of the time variable in low-level physics equations. The math works out fine either way. A Feynman diagram, for instance, describes true particle interactions in all four 90° rotations.) The point I wanted to make is just that entropy can decrease even without reversing any forces.
Brain entropy is like office entropy; we need to define the micro- and macro-states. One neuroscientist said the synapse is the most complicated biological machine we know, and the connectome of the brain is certainly extremely complex. Given that connectome, just the firing/not-firing state space of the brain is enormous. One rough estimate I made put it at 10 to the power of 4,800,000,000,000,000.
Brains also have function, which makes things more complicated. They’re only in one firing state at a time, so in that sense they have zero entropy. Presumably consciousness is limited to a small number of the possible states, so consciousness seems low-entropy. Brain physical structures are rather singular, so structurally brains have low-entropy. The only place I see much entropy in a normal functioning brain is in the waste heat and chemical byproducts produced by the brain maintaining its low-entropy state. I think the complexity of the brain suggests they’re overall objects with notably low entropy. Which means they necessarily produce a fair amount in the process. Some body organs might come close, but I suspect brains stand out. As you mentioned, they consume a large fraction of our total energy production.
I would say complexity links to entropy in defining the maximum possible entropy a system can have. The max entropy of a small CD collection (or of a sparse office) is lower than that of a large CD collection (or busy office). But a complex system can be in a singular state and have, at that moment, low entropy (even zero). The CD collection perfectly sorted, for instance.
I don’t give a great deal of weight to the epistemic view. I see entropy as a derived emergent notion, and our ability to quantify it as even more removed. Often we can’t quantify it precisely and it remains an abstraction. In small systems where can measure heat, or in simple models, it’s a precise notion, but in more complex systems the notion becomes slippery.
LikeLike
Thanks. I get the distinction between maximum entropy and the entropy of whatever the system is current in. A zeroed out ram chip has less entropy that its maximum. What I’m less sure of is the significance of the system being in any one state at a time. Isn’t a heap of ashes (generally considered a high entropy state) in only one state at a time? If we do eschew the epistemic view, what distinguishes its state from the other things you mention? It doesn’t seem like it can be due to functionality, since ashes can be put to use (fertilizer, making soap, insect repellant, etc). Granted we have to inject energy, but that seems true with the others as well.
LikeLike
Sure, I get what you’re asking. It’s something I didn’t mention. Part of the definition of a macro-state is that all states that belong to it are somehow indistinguishable. It’s another pile of weeds to get into, so I left it alone. 🙂
What distinguishes one pile of ashes from another? If we’re burning wood, we can distinguish each piece on its major physical characteristics, but how to tell one pile of burned birch from another pile of the same wood? If we burn the pages of a book, also easily distinguished objects, what makes one pile of paper ash different from another?
It’s the indistinguishability of states that causes them to have the same entropy. Piles of ash have high entropy because all combinations of the same burned object look pretty much identical, and they look identical to other similar burned objects. So the size of the ash macro-states is much larger (i.e. has higher entropy) than the size of the unburned object ones.
Indistinguishability can be tricky. In the CD example, the lowest non-zero entropy state is the one-CD-out-of-place state, and at first blush, all those combinations of which CD and where it’s placed might seem distinguishable from each other. Indeed they are. But they share in common that restoring perfect order involves a single scan for a single error and a single swap operation to correct it. The same simple procedure works for all cases of one-CD-out-of-place. To that procedure, all cases of that macro-state look the same.
And you’re right about functionality; that’s not an issue here. Burning removes some of the atoms, and breaks down molecules, but that leaves other compounds that have value.
LikeLiked by 1 person
“One rough estimate I made put it at 10 to the power of 4,800,000,000,000,000.”
This is why we always check each other’s math. I grabbed the wrong number from that post. Assuming 100-billion neurons, the state space of neurons firing/not-firing is only:
Which is still a pretty big number. Over 30-billion digits. (OTOH, I think it’s very likely neuron firing state is too high-level to capture the mind, so I’m sure our actual state space is much larger.)
LikeLike
Entropy is a difficult subject, but I can at least answer your opening question, about who decides what qualifies as disorder. I think you have a good question. (And I can relate; in my study I know exactly where everything is in until someone tidies it up for me).
The answer is that a calorimeter decides. Science is about measuring, and the way that entropy is measured is by sticking a thing into a calorimeter to see how much heat energy it has.
In thermodynamics, heat is the random motion of particles, and so heat, randomness, and disorder are closely related entities. If given one, it becomes easy to calculate the other.
Imagine trying to measure how complex something it, as in putting a number on it. It proves very difficult to measure how complicated something is, since there are all kinds of ways of being ordered, and we can’t cover all of them with any certainty. So the remedy is to measure the opposite of complexity, which is disorder, because we can do so simply with the calorimeter. Then if we want to, we can talk about “negentropy,” which is entropy with the opposite plus or minus sign in front of it. And with that, we have a way of measuring the degree of complexity. And from that we can make predictions, especially in the sense of finding if chemical reactions will be possible or not.
Thus, when it is said that entropy always increases during a physical process, that means that some heat is always lost into the environment during the processing. In other words, no physical process is 100% efficient. Some of the original complexity that was originally there has to be converted back to randomness that is lost as escaping heat. And from that it can be said that the entropy of the Universe is always rising.
Then as for the brain, it is low entropy in its organization by virtue of its complexity. But as it does its work, it gives off entropy (heat, disorder) to the environment. Still, that entropy doesn’t stay in the brain—it goes to the environment—so the brain itself is not thereby high in entropy. It remains low entropy (highly organized).
LikeLiked by 2 people
Thanks Deal. I’m grateful for the explanation. Good point that terms like “disorder” and “random” are useful heuristics to get at measurement. That makes sense. I think my issue with popular science descriptions, is that’s what they use, and then just stop. I suspect I’m far from the only one who doesn’t understand those accounts. It also helps to just admit that scientists themselves often debate the exact nature of entropy.
Your description made me lookup “calorimeter”, which ended up reminding me of the concept of enthalpy, a system’s overall internal energy. Thanks!
In terms of brains, I used the word “high” in the post, but I don’t know that anyone is saying brains necessarily have high entropy, although I don’t know that the word “low” makes sense here either. It may not have much more entropy than a lot of other systems, but what’s interesting is the idea that it uses its entropy. Of course, this is just another way of saying it processes physical information, or even semantic information once we get insights into what’s happening.
LikeLiked by 1 person
Thanks. I really think your question in your essay (who decides the criteria by which something is ordered or disordered) is the perfect opening to a discussion of entropy. Good going.
I also have to tell you that you got me thinking more about your analogy to accounting, regarding how sometimes you have to forget preconceptions to understand the new. I keep seeing that idea popping up. For instance, Freeman Dyson (Feynman’s sidekick), in his last essay before he died last year, talked about having to dispel the notion that it as a peaceful calm Universe before being able to discuss how it dynamically changes, such as expansion and the Big Bang. (Dyson was reviewing the book Zwicky about an astronomer in the 1930’s). I’d send you the link except that they make you pay. Anyway, if you are at all inclined to expand on what you meant with the accounting or any other example, I would be extremely interested. Dyson called it “morphological thinking,” to clear one’s mind in order to see new things.
LikeLiked by 1 person
Thanks. It seems like it comes up a lot in science. Consider special relativity. Understanding it means letting go of some intuitive concepts, like just one now pervading the entire universe. In the case of general relativity, it means letting go of the idea of space as something static and unchanging, accepting that it can be shrunk, expanded, and warped. And quantum mechanics means letting go of…something. (Exactly what depends on which interpretation you favor.)
There are lots of others, but they get into increasingly controversial territory, such as letting go of the idea of a theater of the mind in trying to understand consciousness.
LikeLiked by 1 person
We all agree that information is a key component of life, and we humans have legitimate interest in information related concepts like entropy or causality. But living entities care mostly about meaningful information. It can be a starting point for an understanding of information.
As some of you know, an evolutionary approach to the concept of meaningful information allows to model meaning generation for basic life. The model can be extended to animals, humans and artificial agents (short presentation at https://philpapers.org/archive/MENITA-7.pdf)
Such perspective does not bring much on concepts of entropy and causality. But it introduces an evolutionary approach to our human mind which is the source of all our scientific concepts …
Have a nice reading.
LikeLiked by 2 people
Thanks Christophe. Looks like an interesting paper. I just skimmed it, but need to swing back around and give it a more careful pass. I’m onboard with an evolutionary approach for getting at meaning, at least for evolved systems.
LikeLike
Thanks. Your comments will be welcome.
You may also be interested by a presentation about an evolutionary approach introducing the concept of meaning in evolution. It is based on a local ’maintain status’ constraint that comes in addition to ubiquist physico-chemical laws (present everywhere) in a pre-biotic universe. (See https://philpapers.org/rec/MENICA-2)
LikeLiked by 2 people
Wyrde and Deal both made an excellent point, which I initially missed. The brain is of course an example of a *low entropy* system, on account of its highly structured, ordered state. Life in general is structure, which is why it is ultimately doomed.
LikeLiked by 1 person
I’m not sure I’d use the label “low entropy” with the brain, but as I noted to Deal, it may not be extraordinarily high in entropy either. It’s distinguishing feature appears to be its utilization of its entropy, which may just be a fancy way of saying it’s an information processing system. But that utilization of entropy is likely why so much of the body’s energy budget is dedicated to it. Information processing has a thermodynamic cost.
LikeLike
Information processing definitely has a thermodynamic cost and brains are definitely information processing machines.
LikeLiked by 1 person
Mike,
Between physical information and semantic information, I wonder if you’d consider it useful to identify a “machine information”? This would be algorithms that operate machines, whether engineered or evolved, that gain no meaning from their function. The heart functions this way as well as a remote control car. Does that seem like a useful distinction to you as well as the other two?
LikeLiked by 2 people
Eric,
You say the algorithms that operate machines gain no meaning from their function. But if I build or use a machine, are you saying its function, algorithms, and information have no meaning for me? If so, why do I build or use it?
Granted, if a future archaeologist finds the machine and doesn’t understand its function, it’s operations might be meaningless for them, at least at first. In this case, it’s similar to (although perhaps easier than) a biologist trying to understand the processing of an evolved organism.
In all cases, we have physical information processing. But once someone understands the function of the machine, we seem to have semantic (meaningful) information. What would distinguish machine information, in the sense you’re using “machine”, from the other two?
LikeLiked by 1 person
No Mike, it’s not about these machines having no meaning for you. I’m quite aware that the function of machines can be meaningful to you and people in general. As you mentioned, why else would we make them? Instead it’s having no meaning for the machines themselves. Presumably the algorithmic function of a heart has no meaning to that heart. Or the algorithmic function of a robotic car has no meaning to that car. Between your provided physical information and semantic information, I wonder if you consider it useful to designate a “machine information” that’s meaningless to those machines? It’s a smaller domain than physical information because here there’s either an evolved or engineered “machine”, and it’s a wider domain than semantic information because here there needn’t be any understanding but rather just associated algorithmic function. Do you consider such an information distinction useful? Or if not then I’d be curious why not?
LikeLiked by 1 person
Eric, I see you and Christophe are talking about this below. I’ll just note that I don’t think there’s anything special about the information, in and of itself, used by a conscious agent. It’s use by that agent implies it’s meaningful to that agent. On how much like us another system needs to be for information to be meaningful to it, I don’t think there’s a fact of the matter answer.
LikeLiked by 1 person
That’s fine Mike, though it’s not quite in the form of yes you do consider machine information to be a reasonably useful distinction (or a form which animates the function of either evolved or teleologically engineered machines (such as hearts and robots that do not phenomenally experience their existence)), or that you don’t consider this distinction reasonably useful and have some sort of explanation for that. But of course you needn’t answer my question if you’d rather not.
In any case you might ask why I consider “machine information” to be a useful idea. Well first, the “physical information” that you present seems rather esoteric. Apparently something with high entropy, such as a perpetually isolated atom in space at absolute zero, has high entropy because it doesn’t really do work anymore. Furthermore if I understand you right it also carries a lot of physical information in the sense that it must have done a lot of causal stuff over time in order to eventually get that way. Fine, but in my own life I don’t have much use for information in that form. (I will say that I like that you’ve stopped referring to information as causation however, since in the past you’ve used that heuristic to imply that there’s nothing otherworldly about non mechanized processed information existing itself as phenomenal experience.)
The concept of machine information is far less universal. So how am I defining “a machine”? The origin is not just in normal causal function, but evolved causal function. Here all living things would be “machines”, and usually not otherwise. They accept machine information from their surroundings and react in ways that tend to help them survive. Furthermore many forms of life developed central machine information processors, or brains. Here they process machine information into algorithms that operate various types of machine within them, or even outside if they can manipulate other machines. Here brains may effectively be referred to as computers.
Once machines began to phenomenally experience their existence it became possible for them to teleologically create machines of their own that weren’t alive. Nevertheless most life doesn’t seem to do so. During its civilization however the human has come to create progressively more advanced machines. Furthermore some of these machines may also be referred to as “computers”, or machines that accept input machine information (or algorithms), and process it in order to produce new algorithms that animate the function of other machines either within or outside of them.
Maybe now you can tell me if you consider this “machine information” to be a useful idea?
LikeLiked by 1 person
Eric,
I tried to make it clear in my previous response why I don’t consider it a useful distinction. You seem to be trying to make some kind of distinction between information in a conscious vs non-conscious system. I don’t think that distinction, for the information itself, is meaningful. We could probably talk about the different ways that information is used, but that just gets into the usual arguments about consciousness.
The distinction you’re trying to make does have some similarities to David Chalmers’ dual aspect theory of consciousness, the idea that information, or in this case some information, has phenomenal properties. Since I see those properties as being composed of information and its processing, not an aspect of the information, it’s not a theory I’m enamored of.
Physical information is the concept of information used in physics. I guess that is esoteric to some degree, but then so is most of science. The main thing to understand about physical information is that it’s a superset of semantic information. To say something is physical information but not semantic information is, to me, just to say we don’t yet know the possible semantics, the meaning, of that information (or “data” if you insist).
LikeLiked by 1 person
Mike,
I’m not sure what I said to make you think I was talking about a distinction between information in conscious versus non-conscious systems. I could make that distinction by noting that there should be certain “hard problems physics” associated with the conscious kind, and other such details as we’ve discussed before. I didn’t however because I’m talking about something else. This is an information distinction which is narrower than your physical information and broader than your semantic information. It’s a kind associated with the function of both the machines that we create, as well as the machines that evolution creates. Biologists and engineers should have uses for such an information distinction.
If David Chalmers believed that there were causal mechanisms of this world by which certain organisms experience their existence (perhaps certain forms of electromagnetic radiation?), then I’d be able to give his ideas more credence. At least in that case he’d be proposing something that’s potentially testable. As things stand today it seems far less problematic for people to propose unfalsifiable ideas.
LikeLiked by 1 person
Eric,
My impression of the consciousness vs non-consciousness distinction came from the remark you made above about the information being meaningful to the machine itself, and your first response to Christophe below discussing “functional consciousness” or “phenomenal experience”.
If we’re talking about information used in any functional manner, well, that’s a matter of interpretation, of semantics. Let’s consider three examples.
1) Gravitational waves. Prior to a few years ago, we weren’t sure these existed, although Einstein’s general relativity predicted them over a century ago. We now know that those waves have always existed. They propagate throughout the universe, stretching and compressing spacetime and having (minute) effects on matter and energy. They are patterns in nature that had upstream causes (black hole mergers, etc) and have downstream causal effects.
2) DNA. Prior to Crick, Franklin, and Watson discovering its function, we didn’t know the meaning of the information DNA contained. We didn’t even know DNA existed prior to 1869. But of course that double helix molecule has been around for billions of years. Again, we’re talking about something that had upstream causes (proteins replicating the molecule) and downstream causal effects (other proteins generating mRNA, which go on to affect ribosomes in terms of which proteins they build). This is a case where we understood the causal effects before we knew where the information lay.
3) This comment, a pattern that exists on the screen of your device, which was caused by a pattern in the RAM chip of your device, which in turn was caused by electrical signals from your network hardware, etc, a causal chain going all the way back to me typing it, which of course has a causal chain going back to my brain state from reading your comment above. So again, we have a pattern that had upstream causes, and that will have downstream causal effects.
I assume you’d classify 2) and 3) as machine information, but not 1). That might have some pragmatic value. But what I want you to think about, is that you can make those classifications because of the semantics, the meaning, you associate with them, or fail to associate. At the raw physics layer, all three remain patterns that were caused, and have causal effects.
So maybe the question I should ask you is, what difference do you see, aside from that functional semantic interpretation, between machine and non-machine information?
On Chalmers’ double aspect theory, yeah, he makes a distinction between the physical aspects of information and its phenomenal aspects. I’m sure we both agree we don’t need to go beyond the physics.
LikeLiked by 1 person
Okay Mike, going over what I said I can see how you could have missed that when I was referring to meaning, it was in terms of *not* what I was talking about for machine information. And indeed, apparently Christophe’s use of the term in his original comment to me did not refer to phenomenal experience either, though I can see how you might have gotten the wrong idea when I was trying to establish what he meant. Apparently that’s settled now.
On the non semantic difference I see between machine and non-machine information, actually anything that I understand will inherently be semantic. So unless I respond with nonsense which doesn’t even make sense to me (and that’s a road I try to avoid), I will be providing something semantic. The semantic distinction which I was making above and I consider useful, is that while something created intelligently or through evolution will have at least apparent purpose (if not actual purpose), the rest of reality seems not to. So people who study evolved machines, as well as those who build machines, ought to have uses for what I’m calling machine information, or a subset of what you’re calling physical information.
Furthermore within machine information I think it’s useful to identify a computational form. Computers are not only animated by the information that they receive, like a non computational windmill is animated by wind for example, but they can potentially process that information algorithmically into new algorithms that animate the function of other machines. This is the relationship of a normal computer to a monitor, a brain to a heart, and controversially a brain to not yet established mechanisms that create phenomenal experience. Only in this final form would machine information get into meaning or purpose in a phenomenal capacity. My single principle of axiology states that it’s possible for a computer that does not experience its existence, like a brain, to produce a punishment / reward dynamic from which to drive the function of a computer that does experience its existence, like you or me. Thus here I propose a phenomenal computer within a non-phenomenal computer, or a dual computer dynamic. And as phenomenal computers, what’s the substrate of you or me? As you know I suspect electromagnetic radiation caused by certain varieties of synchronous neuron firing.
LikeLiked by 1 person
If we understand semantic information as information meaningful for an agent we can consider machine information as information meaningful for an artificial agent. There is a model of meaning generation that allows that (https://philpapers.org/archive/MENITA-7.pdf).
Engineered or evolved algorithms can then make the difference by the constraint to be satisfied associated to the algorithm (circulate blood to stay alive or pump blood as programmed by artificial heart designers).
LikeLiked by 1 person
Christophe,
By “meaning” I’m actually referring to something with functional “consciousness” or “phenomenal experience”. While I can honestly say that existing as myself feels like something, I presume that existing as my heart feels like nothing at all, and even if my own existence happens to be dependent upon such a blood pumping machine. So do you mean meaning as I’m using the term, and so you consider functional machines like hearts to phenomenally experience their existence given that their algorithmic workings make cognitive sense to them, or rather the far less disputable idea that hearts have meaning in the sense that algorithms animate them to do what they do, though they remain oblivious to their existence in an experiential sense? I’m simply curious about your position given that we might be aligned. I’m not here to belittle those who see things differently than I do, if that does happen to be the case.
LikeLike
Eric,
There are some differences. “Meaning” for me is active information in an agent that has a constraint to satisfy. The meaning is the connection existing between the constraint and a received information (ex: non compatibility between a “stay alive” constraint and a received information, like detection of toxic material). The meaning will be used by the agent to implement actions to satisfy the constraint (get away from toxic area). So “phenomenal experience” is not needed. It can exist for living entities but the model for meaning generation does not need that concept. A robot programmed to avoid obstacles (the programmed constraint) will generate meanings when detecting an obstacle. Robots generate derived meanings coming from derived constrainsts. Phenomenal experience is not needed.
Now, addressing the possible phenomenal experience of a heart is not an easy subject. I would say that a heart exists only as part of the organism it serves. It has no being by itself. It looks preferable to consider a heart as participating to the satisfaction of the constraints of the organism that contains it. So for me hearts do not “phenomenally experience their existence”. Such performance is present at the level of the organism, not at the heart level.
LikeLiked by 1 person
That’s good to hear Christophe — we were simply using the “meaning” term in different ways, me phenomenally and you as a standard engineered or evolved machine should function. Furthermore this suggests that you consider it useful to identify a machine information distinction between Mike’s physical and semantic forms. Great! Let’s delve into that a bit further.
As I understand it computers function by accepting input information, processing it by means of AND, OR, and NOT gates, and then producing output algorithms that are set up to animate the function of various machines. For example your computer screen’s pixels should be lit up by means of such algorithms. It’s thought that the brain functions this way also by means of neuron firing, with the heart being an obvious machine that it animates. Regardless my point is that in order to do what they do, computers seem to exclusively animate various mechanisms.
So now let’s get into the famous hard problem of phenomenal experience. From this model brains must animate certain mechanisms in order to create a phenomenal entity. But popular modern consciousness proposals seem to take a shortcut by proposing that the right algorithms are all that brains need to produce, not algorithms that animate phenomenal experience producing mechanisms. And how might algorithms even exist in a mechanism independent way? Beats me! I consider algorithms mechanism specific exclusively.
Various distinguished philosophers have developed thought experiments which demonstrate the implications of this shortcut, such as Searle’s Chinese room, Block’s China brain, and Schwitzgebel’s USA consciousness. Then there’s my own thumb pain thought experiment. The premise is that in order for popular consciousness theorists to be correct, then if the right information on paper were properly converted into some other set of information on paper, something here should experience what you do when your thumb gets whacked! That’s the power of mechanism independent algorithms — from here anything seems possible.
The strange thing is that to stay on the right side of naturalism, all these popular theorists would need to say is that their theories do not address the brain mechanisms which actually create phenomenal experience, but rather the processes which animate such unknown mechanisms. So I don’t exactly consider science to have failed here, but rather philosophy. Until philosophers are able to make scientists pay for their funky indulgences, those indulgences should continue to be taken.
LikeLike
Eric,
The way I use the term “meaning” is relative to meaning generation in a system approach that can apply for animals, humans and artificial agents. Such meaning generation can also be used to look at today limits of AI. A paper using meaning generation for the Turing Test, the Chinese Room and Symbol Grounding Problem tells more on that (https://philpapers.org/rec/MENTTC-2). It is not about how “a standard engineered or evolved machine should function”.
The hard problem is “the question of how physical processes in the brain give rise to subjective experience.” Such formulation is a bit confusing because the brain is made of ‘biological processes’ which introduce performances not present in natural physical processes (representation, meaning, ..). Taking life, rather than matter, as a starting point for an understanding of human mind looks to me as more pertinent.
Also, human phenomenal consciousness (what it is like to feel so and so, and to address such feelings) needs self-consciousness (the feeling of being an existing entity able to think). All philosophers do not agree on that, but I feel that reflective self-consciousness is unavoidable when talking about phenomenal consciousness. And this brings the subject to begin by an understanding of self-consciousness. An evolutionary perspective can make available a scenario about a possible nature of self-consciousness. The scenario is based on evolutions of representations and intersubjectivity (https://philpapers.org/archive/MENPFA-4.pdf). We are far from computer type algorithms.
Phenomenal consciousness, being close to first person perspective in self-consciousness, should then be inttroduced quite naturally.
As you say, philosophers have some responsibility in the today difficulties with these subjects. This partly because philosophy has been neglecting evolutionary approaches.
LikeLiked by 1 person
It seems to me that we’re at least on the same team Christophe. Of course the devil is always in the details. What do I believe that seems crazy to you, and/or the other way around? It’s why I was open to you believing that a heart might phenomenally experience its existence. Furthermore I’ll admit that I’m not always as patient with formal academic papers as I might be, that is unless I’ve been given sufficient informal reason for excitement. This happens occasionally.
For all his acclaim, John Searle is one of the philosophers that I believe hasn’t done a good enough job. His Chinese room argument seems too technical and complex to truly hit his theme home. Furthermore it’s based upon the hypothetical invention of a machine that he never thought possible. In any case he seems not to have blunt the popularity in science today for “algorithm only” consciousness proposals. And of course it didn’t help that his career was terminated by his disgraceful treatment of women underlings.
I consider my own thought experiment a possible way to shake up the status quo. If it were generally known, how many respected intellectuals would admit that the right paper based algorithm that’s properly converted into another such algorithm, should create something that experiences what we do when our thumbs get whacked? Even if few change their position, I doubt that younger people would so easily be indoctrinated as they seem to be today.
If brains not only create algorithms associated with phenomenal experience, but those algorithms can go on to animate the function of various phenomenal experience producing mechanisms, then what might those mechanisms be? I think the UK microbiologist Johnjoe McFadden makes a strong case that they probably exist as some form of electromagnetic radiation associated with certain synchronous neuron firing.
In any case I we can go on here, or if you’re interested there’s always email. thephilosophereric@gmail.com
LikeLike
Not sure, Eric, I understand you about Searle. He has proposed an experience showing that the Turing Test (TT) is not valid for testing machines thinking capabilities. This was an acheivement.
In the TT a computer is to answer questions asked by humans. If the answers are not distinguishable from the ones made by humans, then the computer passes the TT. So the TT addresses the capability for a computer to understand questions formulated in human language and to answer these questions as well as humans would do. The Chinese Room Argument (CRA) challenges the TT by showing that a computer can pass the TT without understanding symbols [Searle, 1980]. A person not speaking Chinese and exchanging Chinese symbols with people speaking Chinese can make them believe she speaks Chinese if she chooses the symbols by following precise rules written by Chinese speaking persons. The person not speaking Chinese passes the TT. A computer following the same precise rules would also pass the TT. In both cases the Chinese symbols are not understood. The CRA argues that the TT is not valid for testing machine thinking capability as it can be passed without associating any meaning to the exchanged information.
Regarding your argument about paper based algorithms not capable to induce experiences, I agree if there is no living entity in the process. Experiences suppose living entities to feel the experience. No living entity => no experience. For artificial agents (AAs) to become capable of feeling we need to somehow transfer them the performances of life, we need to bring life in AAs. Sort of “meat in the computer” (see https://philpapers.org/rec/MENTTC-2).
The same can be said about mechanisms capable to produce phenomenal experiences. These mechanisms have to be part of living entities to allow the possibility for feelings. (AAs do not feel. They just function). For animals, we can know the process leading to a possible feeling (ex: pain) but we do not know the content of the feeling (what it is like for an animal to feel pain). We can only try to extrapolate to animals what we understand about our human feelings. But that understanding is very limited, and it will remain so until we know the nature of self-consciousness (see my previous post).
LikeLiked by 1 person
Christophe,
With a bit of divergence I do generally agree with your interpretation of the CRA. Nevertheless I think we should formally acknowledged that our side has failed so far. Popular modern consciousness theories such as GWT, IIT, AST, and so on, flout the CRA, as well as Block’s China brain, Schwitzgebel’s USA consciousness, and so on. So is it now sensible to say that our side has done a good job? I don’t see how it could be. Surely it’s not right for us to postulate that people on the other side have simply been too stupid to understand. Instead we should ask why it is that our arguments have been unpersuasive, and certainly how they might be improved. Otherwise I don’t think we actually deserve validation, and even if we do happen to be on the right side of this debate.
Like yourself I’m not satisfied with using Turing’s heuristic for testing the existence of consciousness. Observe that we presume consciousness in all sorts of non human organisms which can’t pass this test. So why decide that consciousness requires one of our machines to not only be like one of these organisms, but also be so ridiculously beyond them that it can actually talk with us intelligently? Even humans can’t do so without years of instruction. Here we’re not only asking such a machine to phenomenally experience its existence, but in the fashion of an educated version of the most evolved creature on our planet. And yet because we can easily make non-phenomenal computers answer yes/no questions in a way that seems reasonably human, and theoretically more and more advanced algorithm processing might permit them to produce more and more detailed responses, the presumption has been that some day our machines will experience their existence by means of algorithm processing alone!
The logic of this seems quite unfounded to me. Apparently our side made a critical mistake by even entertaining their proposal at all (and I include Searle’s CRA to be part of this flawed entertainment). Today I think we should formally admit our mistake and proclaim that it’s not the appearance of human language that should be focused upon, but rather the appearance of phenomenal experience itself. Thus we should build thought experiments (and hopefully empirical experiments), that are focused upon phenomenal experience itself, not a far distant relative such as spoken human language. In these efforts consider a full rendition of my own such thought experiment.
When a hammer strikes your thumb, experimental evidence suggests that algorithmic information about this event is conveyed to your brain by means of sensory nerve signals. Furthermore it’s thought that these algorithms are processed there by means of the potential firing of billions of neurons connected by trillions of synapses. In general when the brain receives applicable sensory nerve algorithms, it processes them to create output algorithms which go on to animate the function of various machines such as muscles which control heart function. The one exception to this rule however is that it’s popularly theorized that unlike other output function, the brain needn’t animate any phenomenal experience producing mechanisms whatsoever. It’s thought that when sensory nerves provide the brain with algorithms associated with a whacked thumb (which it then processes by means of associated neuron firing and whatnot), that the processing alone should create that experience. This is odd in the sense that all other known brain function depends upon its algorithmic animation of mechanisms, such as the ones that produce hormones like testosterone by means of the gonads. What are the implications of phenomenal experience existing through algorithm processing alone without any other mechanistic instantiation?
Observe that if nerve information correlated with a whacked thumb were instead expressed on paper, and that paper were properly processed by a vast scanning and printing computer into another set of information on paper correlated with associated brain processing, then something here should experience what you essentially do when your thumb gets whacked! I have no idea what would do this experiencing since were merely discussing properly inscribed paper that’s put through a machine to properly create another set of inscribed paper. But theoretically “processed information alone” theorists hold that something here would nevertheless have such an experience.
The main reason that I consider this scenario ridiculous is because in a causal world, algorithms should only exist as such by means of associated instantiation mechanisms. The algorithm of a shopping list should not exist as such in respect to a dog, but rather in respect to a person who is able to decipher it. Similarly the algorithm of a VHS tape should not exist as such except in respect to a machine that’s able to display its video content. Nevertheless popular consciousness theorists today seem to bypass a famous “hard problem” by instead theorizing the existence of algorithms that are mechanism independent. As such these proposals seem no more falsifiable than the existence of God.
If we had paper with markings on it that was effectively correlated with the information that nerves send your brain when your thumb gets whacked, and it were somehow processed into another set of paper with markings on it effectively correlated with your brain’s response, you might ask what it should take in order for something to actually feel what you do? Naturalism suggests that this second set of paper would need to be fed into a machine that’s set up to use it by means of the same phenomenal physics that your brain uses for you to experience existence. Furthermore I suspect that Johnjoe McFadden is miles ahead of anyone else on this front, and so such an experience would exist in the form of a specific field of electromagnetic radiation that such a machine would produce. Unlike unfalsifiable algorithm only proposals, this happens to be testable. (Actually I’ve proposed a way to test his theory.) The problem seems to be that money in general is spent to support popular algorithm only proposals, and they’re fundamentally untestable given their instantiation mechanism void.
I’d also like to say that I agree with the spirit of your position of how inferior human engineering happens to be when compared against the work of evolution. I don’t believe we should ever expect to create machines that are able think even somewhat comparably to us. Still there are two reasons that I think we should beat this particular drum softly. The first is political. If we explicitly deny each outlandish musing of the other side about how the human will create advanced thinking machines, then we come off as small minded oppressors. Here I’d advise us to instead smile and be polite. Theists should be handled this way as well I think. But secondly there seems to be a danger of them legitimately faulting our naturalism here. If we posit that some mysterious “life stuff” is the reason that the brain is able to create human thought, then we effectively become substance dualists like Chalmers and all the rest. Instead I think we must formally acknowledge that if a human made machine were to implement the physics used by the brain to create phenomenal experience, then that machine must also experience its existence in some manner by means of such physics. Though Searle was also very explicit about this possibility, I’ve noticed many to get him wrong on that count, and even once a now prominent graduate student of his!
LikeLiked by 1 person
Eric (answer to your Oct 24 comments),
your recommendation about focusing more on phenomenal experience than on language illustrates two camps in philosophy of mind: phenomenology and analytic philosophy where ‘phenomenal experience’ or ‘language’ drive research activities. Both sides have however neglected evolution, which is surprising when we accept that human minds are the result of the evolution of life (S. Cunningham tells us in ‘Philosophy and the Darwinian legacy’ that this began with the founding fathers). Phenomenology has build up a ‘phenomenal consciousness’ which considers self consciousness only in the form of a pre-reflective self-consciousness (to take care of the performance of reflectivity).
As you know, I feel that evolution is to be considered as a background for an understanding of human mind. An self-consciousness can be a driver as an evolutionary scenario allows to take into account self-consciousness as subject. Also, the ‘ineffability of qualia’ is to be looked at more closely as reflectivity can be part of the same evolutionary scenario (https://philpapers.org/archive/MENRAA-4.pdf).
A lot is still to be done with these interesting subjects….
LikeLiked by 1 person
Agreed Christophe that there should be plenty left to do in these interesting subjects. I’ve likened them to a physics which is still waiting for the rise of its Newton — they seem not to have progressed anywhere near as far as I think they will. I’m hopeful that my own evolution based model will ultimately succeed (even if it turns out that I personally lack the skills to see it through). My own account begins with why and somewhat how phenomenal experience itself evolved, and then takes this theme on to a psychology based model of modern human function.
I see that your work presents a model of what transpired in order for something like a great ape to evolve into us. Beyond evolution itself I wonder if you can give me a concise theme or description of your position? Most seem to at least believe that their models are evolution based. How would you argue that your ideas do better in this regard? I’m big on effective reductions!
LikeLiked by 1 person
(Answer to your Nov 3rd post)
Eric, In a few words what I’m looking at is a possible evolutionary scenario linking pre-human primates to humans. The former were comparable to our today non-human great apes, and the latter are characterized by human self consciousness (the capability to represent oneself as an existing entity that can be thought about: self-consciousness & introspection).
The nature of life is not addressed. Life is taken as a given with its performances like the management of meaningful representations (networks of meanings; see https://philpapers.org/archive/MENITA-7.pdf). The evolutionary scenario proposes a build-up of self-consciousness that comes with a specific human anxiety (source of an evolutionary engine and possible entry point to human evil). See posters https://philpapers.org/archive/MENPFA-4.pdf and https://philpapers.org/archive/MENSAH.pdf (sorry to repeat).
The differences in our approaches may be in our starting points as you seem to take into account some human characteristics from the beginning.
Different approaches, but many are the ways…
LikeLike
Hi Mike, Brief 2 cents: Data, or information exits regardless. We can measure it (somewhat) depending on our tools. That then depends upon how accurate are those tools and why we care. Which is an uncertainty in itself.
LikeLiked by 1 person
Sean Carroll touches on the relationship between entropy and information in his latest AMA. From the transcript: https://www.preposterousuniverse.com/podcast/2021/10/14/ama-october-2021/
There’s more at the 2:45 mark about why physicists consider information to be preserved when a book is burned and how entropy figures into it. My summary take, related to what I said in the post, is what’s preserved is physical information, but not information that remains semantic for human purposes.
LikeLike
I think the unitarity of QM is one of the things that will turn out to be not quite true. (I assume that’s what said at the 2:45 mark?)
Thing is: Do we believe information can be created? If so, why can’t it be destroyed? Also: Our physical conservation laws are based on symmetries, but what symmetry is conservation of information based on? I think the notion deserves reconsideration.
It would certainly resolve the black hole information paradox! 😉
LikeLike
He didn’t really touch on QM in that part of the podcast. It was all in classical terms. Of course, this is Sean Carroll, so he touches on QM several times elsewhere in the episode.
It does stand to reason that if information can’t be destroyed, then it also can’t be created. Similar to energy, it would only be able to be combined, mixed, transformed, etc. Of course, semantically useful information can be created and destroyed. But the physical information which it’s composed of couldn’t.
Unless of course that’s wrong, and we can stop worrying about black hole information. 😁
LikeLike
Right. So here’s one thing I ponder on my walks:
In beta decay a neutron turns into a proton because one of its down quarks turns into an up quark. In the process it spits out a W- that quickly decays into an electron and an anti-neutrino. That short-lived W- boson has a beginning and an ending. The two new leptons have a beginning.
Unitarity means the quantum numbers (charge, spin, etc) are preserved, but it seems like new particles are new information. The life spans and distance from their origin seem to be new information.
Totally agree high-level information is created and destroyed. Given particle creation and destruction, I wonder where the boundary is. Does unitarity only involve the quantum numbers? (If so, black holes are still a vexation.)
LikeLike
I’m out of my depth here, but it seems like the fact that the quantum numbers get preserved means that no information is created. The books seem to stay balanced. The information of the W boson seems like it was inherent in the down quark and its interactions with its neighboring quarks. The randomness of when it decays might tempt us to think there’s something new being added, but at the level of QFT and wavefunctions, it seems like everything works out. Again though, if there’s an ontic wavefunction collapse, that case does seem stronger.
LikeLike
I agree the quantum numbers (mass, charge, momentum, spin, etc.) don’t change, and those books balance, but aren’t distance and decay times also information? I suppose it’s possible distance could be derived from the momentum vector+time. Decay time is random, so I’m not sure how that could be derived. It puzzles me, and given that QM has been stuck for a while, perhaps unitarity is a thing to reconsider or at least take a close look at. Maybe there’s a Newton-Einstein thing where information conservation doesn’t apply to all contexts. 🤷♂️
I’m not sure the question doesn’t apply even without ontic wavefunction collapse!
LikeLiked by 1 person
One symmetry that could, and arguably does, underlie conservation of information is CPT symmetry.
LikeLike
I think I see what you’re going for. What do you think about it requiring CPT (i.e. all three transformations) to avoid violations? (For instance, what, if anything, does CP violation imply for conservation of information?)
I’m seeking something mathematical involving Noether’s theorem. Something like how time translation invariance leads to the conservation of energy. Or likewise with space and momentum.
The thing is, from what little I’ve looked into it so far, “conservation of information” isn’t really a thing in general physics (which is fine with creating and destroying information). It’s a quantum thing based on unitarity. At root it’s about the wavefunction and how decoherence just spreads (quantum) information into the environment — in principle it can always be recovered. Given we know QM is, at best, an approximation, it seems information conservation is in a different class from those based on Noether’s theorem.
LikeLike
I don’t think it matters for conservation of information that CP violation is possible. Conservation of information applies over time, not over space. I think you can reason from CPT symmetry to conservation of information without having a deep understanding of Noether’s Theorem, because I don’t have the latter. But if CPT symmetry holds, and you have the laws of nature and a complete description of a closed system at one time, then it implies a complete description at any other time. That constitutes a kind of conservation of information. CPT symmetry is probably overkill; all you really need is any 1:1 correspondence between states over time. But CPT suffices.
LikeLike
Could be. I’d have to research it a lot more to say. Noether’s theorem has to do with invariance, which is an analog kind of symmetry — invariant translations in space, time, and rotation. The CPT translations are digital — reversals of state. It feels like we’re talking about two different classes of invariance.
FWIW: There is also that CPT translations are kind of abstract — they’re statements about happens when certain signs are reversed. The time, space, and rotation translations that lead to energy, momentum, and angular momentum, conservation are real things that physically occur all the time.
🤷♂️ But who knows. I’ve never seen a link between CPT and unitarity cited before. Maybe you should write a paper!
LikeLike
? That seems to be anything but novel. E.g. https://www.mdpi.com/2073-8994/8/11/114/pdf and https://arxiv.org/pdf/hep-ph/0504143.pdf
Which both go way over my head, but clearly have in mind a strong link between CPT and unitarity.
LikeLike
I took a look, and there’s certainly a link between them, but the papers seem to say CPT is a consequence that supervenes, in part, on the assumption of unitarity. From the first paper:
From the second:
CPT comes off more as an emergent property, than a fundamental invariance. Given XYZ it is the case that CPT.
You had me going there for a minute — maybe there was a basis for information conservation after all — but upon reflection I don’t think it’s that simple. I’m still a bit askance at the assumption of unitarity. 😀
LikeLike
I said that CPT is overkill, more than you need for conservation of information. Which is another way of saying that CPT requires conservation of information but the latter does not imply the former. If you’re looking for an interesting, differently phrased but logically equivalent formulation of conservation of information, I don’t have one. Not in terms of symmetry nor in any other way.
LikeLike
Right, and my point is I’m not sure anyone does. Unitarity, from what I can tell, is an axiom. The CPT link was intriguing to me in the potential for violations that might suggest unitarity isn’t a rock bottom truth.
LikeLike
If you’re not already aware of Chiara Marletto you might find this promo clip interesting. I haven’t looked at the Quanta article yet, but I’ve seen Marletto give two talks about constructor theory (which started with David Deutsch), and at least some of it seems interesting. (Some of it seems a little hand-wavy to me, but I’ve only scratched the surface.)
The application here might their efforts to qualify and quantify the notion of knowledge and other higher information abstractions.
LikeLiked by 1 person
I’ve been keeping an eye on constructor theory, and Marletto in particular. I have read the Quanta piece, as well as a few others, one of which James of Seattle clued me into. She was also recently interviewed by Carroll on his podcast. https://www.preposterousuniverse.com/podcast/2021/10/04/167-chiara-marletto-on-constructor-theory-physics-and-possibility/
I think I get the basic idea. It does seem like another approach for working on theories, or for finding new ways to test them. But I’m not necessarily convinced it’s the revolution it’s sometimes hyped to be, at least not yet.
LikeLiked by 1 person
“Yes, I’m pondering the meaning of meaning. Sorry.” Well I’m going to get into a semantic dispute with you about semantic relations. So there!
To wit you need more for a semantic relation than just causal relations. The symbol has to *track* the signified across some array of possible scenarios, or it is not a symbol that refers to the signified. This might be what JamesOfSeattle had in mind by “Semantic information refers to a specific correlation (out of all the possible correlations).” I would add emphasis on “specific”. If the word “cat” means cat, that implies that there is a (mostly) reliable connection between uses of the word and actual cats interacting with the speaker. A one-off instance where a cat scratches a speaker of ancient Egyptian who cries in pain a sound that happens to match the English word “cat” – that doesn’t count.
LikeLiked by 1 person
A semantic dispute about semantics. Well, I guess I brought it on myself. 🙂
I would note that my statement in the post wasn’t meant to be exclusionary. Obviously just referencing the relation between something’s past and future light cone leaves a lot unsaid. I have to do that in a post to avoid having it be 5000 words long. I accepted JamesOfSeattle’s points as plausible elaborations.
The question I would ask you is, how does the symbol *track* the signified? Are you saying it happens without causal interactions? Or do you mean something other than causal interactions are involved? If so, I’m curious about the mechanics. Or do you just mean come cases might require multiple causal interactions; if so, I’m onboard with that.
LikeLiked by 1 person
The last: multiple reinforcing causal interactions, and/or would-be interactions in similar but not quite identical scenarios.
LikeLiked by 1 person
I’ve struggled with the definition of entropy as well. I think it’s a bit like how there are multiple definitions for the word acid. Each of the different definitions is correct, but one definition may be more helpful in explaining chemical reaction A, while a different definition may make more sense in the context of chemical reaction B. I usually think of entropy as the amount of energy in a system that’s no longer available to do work. When entropy comes up in my research or my writing, that definition seems to make the most sense to me. But I don’t think that one definition encompasses the totality of what the word entropy can mean.
LikeLiked by 1 person
There are definitely multiple definitions. And some sources seem to think they describe different things, that maybe this is more a category than a distinct kind. But most authoritative sources seem to view them as different aspects of the same concept. Entropy as the amount of energy unavailable for work is a good definition. It’s similar to my long time one as the degree to which a system has reached its final transformation.
Where the other definitions might come in is describing how that energy becomes unavailable. The potential for work seems bound up in gradients. If the microstates of the system are such that there are gradients that support and enable each other (think dominoes prepped for a cascade), then we have a low entropy situation. But if the gradients have become separated, fragmented, and isolated, because the system is now in a large number of microstates, often described as “disorganized”, they no longer support each other (think dominoes scattered every which way). Transformations can’t happen. Energy in the system is unavailable for work. Maybe.
LikeLiked by 1 person
Just FYI – There is a new article.
https://www.sciencealert.com/physicists-quantified-the-amount-of-information-contained-by-the-entire-observable-universe
A Physicist Quantified The Amount of Information in The Entire Observable Universe
https://aip.scitation.org/doi/10.1063/5.0064475
Estimation of the information contained in the visible matter of the universe featured
LikeLiked by 1 person
Thanks Victor! I saw the Science Alert one this morning, but hadn’t dug up the actual paper.
From the article:
They come up with 6 X 10^80, which fits with the usual estimate of the number of particles in the observable universe. But 1.509 bits / particle seems low to me.
LikeLike
The ever increasing complexity via biological evolution is thermodynamically driven by maximum entropy production (MEP)!
……………………………………
Nature selects systems that produce more and more entropy! This thermodynamic principle is manifested as life, evolution and even human civilisation!
……………………………………
Discoveries of fire, oil and nuclear
energy are in line with the thermodynamic principle of maximum entropy production (MEP)!
LikeLiked by 1 person
Interesting concept. I’ve often thought that life, by resisting entropy for itself, is effectively accelerating it in the environment. But it never occurred to me to think in those terms. Looks like the concept has been around since 1961, although it seems to be considered speculative in most of what I’m seeing.
Thanks for alerting me to it!
LikeLike